Vikash Sharma
Chief Executive Officer





Retrieval Augmented Generation (RAG) is an architecture for improving the performance of artificial intelligence (AI) models by integrating them with real-time knowledge retrieval systems.
RAG connects large language models (LLMs) to external knowledge sources (internal company data, scholarly research, and niche datasets), documents, and databases to deliver accurate, up-to-date, and factually grounded outputs.
On receiving a query, the system locates and extracts the most relevant information from external databases, documents, or APIs.
This retrieved data is merged with the AI’s existing knowledge to enhance its context and improve its understanding of the query.
With enhanced context, the AI produces accurate, detailed, and contextually aligned responses tailored to the user’s request.

RAG development services & solutions enable organizations to cut retraining expenses by efficiently adapting generative AI models for domain-specific applications.
RAG allows LLMs to generate more accurate responses without constantly retraining on new data, leading to significant cost savings.
Scalable RAG architectures handle high-volume data and complex queries across enterprise workflows without performance drops.
Custom RAG keeps data secure by isolating sensitive information and encrypting third-party APIs to safeguard customer data and IP.
Fine-tuned RAG models minimize false outputs by grounding responses in verified data sources to ensure fact-based answers.
Audit trails in RAG systems ensure adherence to GDPR, HIPAA, and other industry regulations and build stakeholder trust.
Unify fragmented data (internal docs, APIs, databases) into a single searchable hub to accelerate AI deployments.
From internal Q&A and AI-driven support tools to automated document workflows, our custom RAG development services uncover insights and speed up informed decision-making.

We analyze your data ecosystems and business goals to design a custom RAG blueprint, ensuring optimal retrieval accuracy, latency, and scalability.

Our domain-specific chunking (content segmentation) and hybrid embedding strategies extract maximum semantic value from your documents, boosting retrieval relevance by 40%+.

Seamlessly connect SQL/NoSQL databases to your RAG pipeline, enabling live querying of CRM, ERP, or transactional data alongside unstructured content.

We prompt-tune retrieval logic combining vector search, keyword filters, and business rules to pinpoint the most contextually relevant data for each query.

Uncover text, image, and table retrieval with unified embeddings, turning PDFs, scans, and spreadsheets into actionable insights without manual extraction.

As a top RAG development services provider, we optimize LLM prompt routing and fine-tune generative AI models to align outputs with your brand voice.

Our A/B-tested reranking and query expansion techniques ensure top-tier precision, reducing irrelevant retrievals by up to 60%.

Automated audit trails and freshness checks prevent outdated or non-compliant data from polluting responses, critical for regulated industries.

Continuous hit-rate monitoring and retrieval analytics drive iterative upgrades, keeping your RAG model development sharp as data evolves.
Deploy AI that understands your business with source-cited responses.
Get a Custom RAG SolutionOur expert RAG developers and architects deliver high-quality, contextual results for enterprise search, insight discovery, internal copilots, and more.


Implemented RAG-based knowledge system to enhance real-time information retrieval.
Deployed a RAG framework for Hisense to enable context-aware data accessibility.
We specialize in advanced RAG architectures, each engineered to solve specific enterprise challenges with precision, speed, and scalability.
Rapid deployment of baseline RAG for prototyping, using generic embeddings to validate initial AI use cases.
Optimized hybrid search with reranking, reducing irrelevant retrievals by 60% for RAG application development.
Future-proof RAG framework by swapping LLMs or databases without overhauling pipelines.
Dynamic query routing that chooses between retrieval or pure generation, balancing speed and precision.
Error-correction layers that flag and revise low-confidence responses for compliance-driven industries.
LLM-guided optimization, where the model evaluates its own sources for RAG AI development.
Combines enterprise RAG solutions with autonomous agents that self-correct responses for higher accuracy.
Time-weighted freshness prioritization, ensuring trends, news, and policies are always current in responses.
Integrates text, image, and audio data retrieval for richer, context-aware AI-generated outputs.
Secure cross-silo retrieval from isolated HR, legal, and engineering data without centralizing sensitive info.
Context-aware retrieval tuning that adjusts chunk sizes and search depth based on query complexity.
Sub-200ms streaming retrieval, powering live customer support and trading systems with zero lag.
Deploy advanced RAG architectures that combine hybrid retrieval, self-critiquing AI, and live data syncs to slash errors and enterprise-scale trust.
Split documents into the right-sized pieces for better retrieval consistency and increase answer precision.
Pick only the most valuable sections from large datasets to speed up responses while keeping answers relevant.
Remove non-essential information while preserving meaning to lower computing costs.
Combine results from multiple extraction methods to ensure reliability and comprehensive answers.
Reorder obtained results based on relevance scores to deliver the most authentic information first.
Generates hypothetical answers to improve retrieval quality and increase veracity for complex queries.
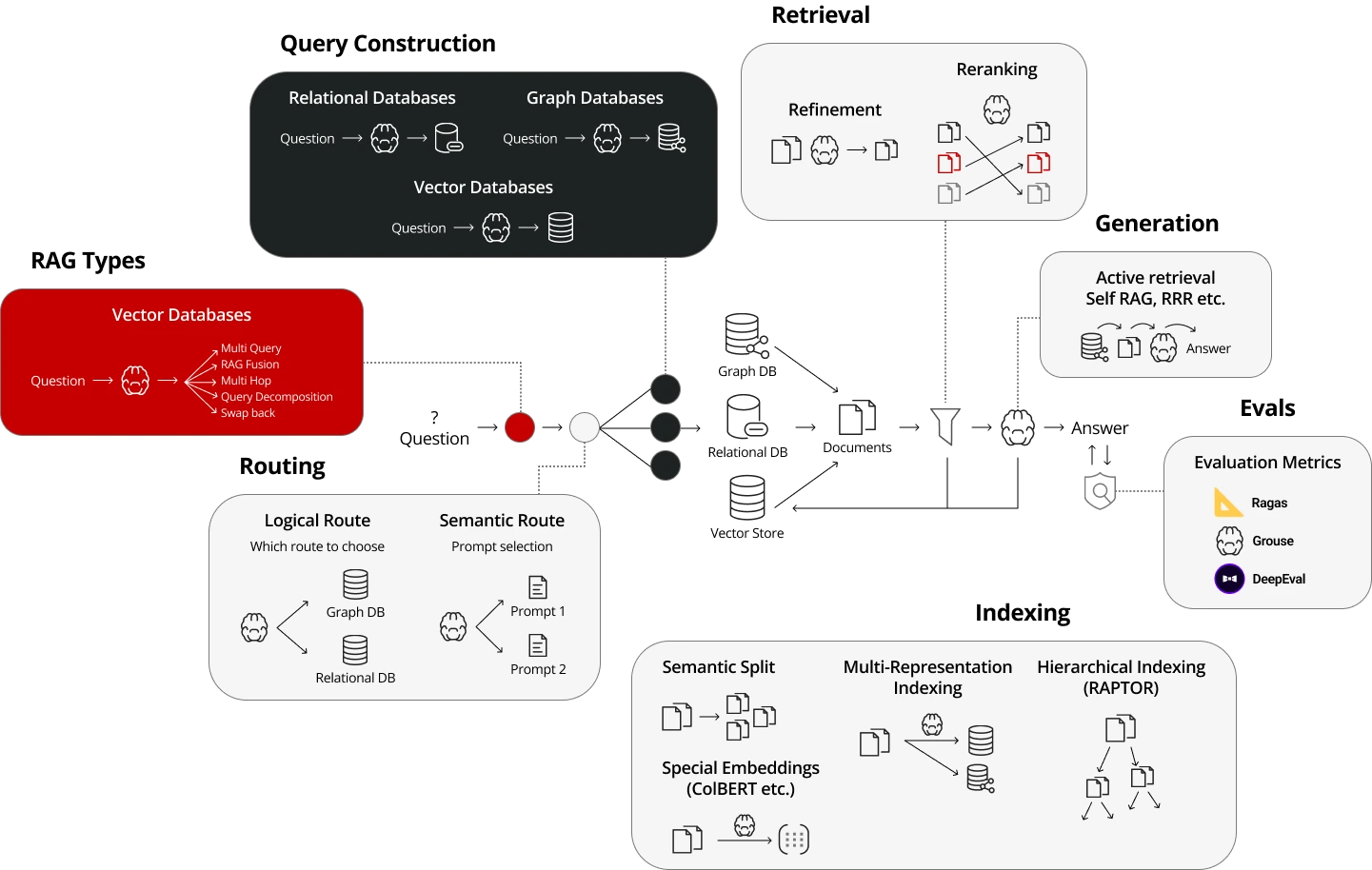
Enterprise-grade RAG architecture precision-tuned to outperform generic AI by 3X.
Talk to Our RAG ExpertsIndustry leaders choose us because we solve RAG's toughest challenges by delivering enterprise-grade AI ethics, compliance, and future-ready architectures.

We eliminate hallucinations, stale data, and poor relevancy through multi-stage validation and live data syncs.
Our context-aware query parsing and structured response templates ensure outputs align with business needs.
Custom hybrid search models that understand your industry’s jargon, workflows, and data patterns, outperforming generic RAG by 40%+.
From day one, audit trails, access controls, and source citations are core to our retrieval-augmented generation development.
Modular LLM-agnostic pipelines that let you swap models or retrievers without rebuilds, protecting your RAG solutions against AI’s rapid evolution.
Scale your AI initiatives with our flexible RAG hiring models. From on-demand RAG professionals to a whole team, we offer RAG services as per your project needs.

Hire dedicated RAG specialists or an entire team who integrate seamlessly with your workflows, ensuring long-term AI project ownership and continuity.

Ideal for defined-scope projects, our fixed-price LLM RAG development delivers predictable budgets with milestone-based quality checks for risk-free execution.

Scale up or down with on-demand RAG developers, paying only for hours used. This model is perfect for agile sprints or pilot testing.
Our RAG development stack uses GPU-optimized vector search and domain-tuned embeddings for enterprise AI applications.
 GPT
GPT Gemini
Gemini Claude
Claude PaLM
PaLM LlamaDALL-E
LlamaDALL-E Whisper
Whisper Mistral
Mistral Vicuna
Vicuna LangChain
LangChain TensorFlow
TensorFlow PyTorch
PyTorch Caffe2
Caffe2 Keras
Keras Chainer
Chainer Nvidia
Nvidia Python
Python JavaScript
JavaScript Docker
Docker Kubernetes
Kubernetes Ansible
Ansible PostgreSQL
PostgreSQL Pinecone
Pinecone MySQL
MySQL Airbyte
Airbyte LangChain
LangChain LlamaIndex
LlamaIndex Unstructured IO
Unstructured IO TensorBoard
TensorBoard Neptune AI
Neptune AI Matplotlib
Matplotlib mlflow
mlflowAs a leading RAG development company, we follow a systematic RAG development process that delivers enterprise-ready AI with measurable KPIs and scalability.


Sparx IT Solutions, they have a professional team that worked dedicatedly from starting to final delivery of my website. I will definitely hire them again.”


I worked with experts at SparxIT for varied projects, including website modernization, end-to-end product engineering, customer experience (CX), and more. They assisted me in transforming and delivering each project with complete dedication.


"Working with SparxIT over the past six to seven months has been an incredible journey. We've just completed the first stage of building the brand’s ecosystem and their team has gone above and beyond to execute the concept with precision. Their support has been remarkable. I look forward to a long-term collaboration and hope to one day thank the team in person for helping turn a dream into reality."


They offered quality solutions within my budget. I would highly recommend them, if someone is looking to hiring a website design and development company. Thanks guys.”


You Tree. Their team not only grasped my business's unique needs but also provided affordable solutions that aligned perfectly with my goals while being responsiveness in tackling every challenge.”
Large Language Models (LLMs) are a core part of AI technology that powers intelligent AI chatbots and advanced natural language processing (NLP) solutions. They aim to deliver accurate answers across contexts by referencing trusted knowledge sources.
However, LLM outputs can be unpredictable, and their static training data creates a fixed knowledge cut-off, limiting response relevance over time. Let’s look at some key challenges of LLMs:
Without RAG, a Large Language Model generates responses only from the data it was originally trained on. With RAG, an information retrieval step is added. Let’s take a look at the RAG implementation process.
By merging retrieval with generation, top RAG development companies deliver results that are timely, domain-specific, and highly reliable.
Retrieval Augmented Generation (RAG) combines the power of generative AI with precise information retrieval. It ensures models produce relevant, current, and trustworthy answers. The architecture relies on several critical components working in sync.


RAG retrieves real-time data from trusted sources before generating responses, ensuring up-to-date accuracy. Fine-tuning adjusts an LLM's internal weights with specific datasets, but the knowledge remains static after training.
Yes. We design RAG solutions that seamlessly integrate with your current AI tools, databases, APIs, and knowledge bases without disrupting existing workflows.
The cost of RAG development ranges from $15K–$30K for entry-level, $35K–$80K for medium-scale, and $100K+ for enterprise-grade solutions, depending on data, integrations, scalability, and compliance requirements.
Typically, deployments take 4–8 weeks, depending on data complexity. As the best RAG development firms for AI projects, we prioritize scalable RAG architectures that deliver fast yet accurate results.
Absolutely. Our RAG systems process PDFs, emails, and documents, transforming messy data into structured, searchable insights.
We implement enterprise-grade encryption, access controls, and audit trails, keeping your data compliant and secure.
Let’s create something extraordinary together.

Explore our latest blogs - a blend of curated content, and trends. Stay informed, and inspired!
Innovative artificial intelligence (AI) solutions are implemented in the insurance sector to enhance efficiency, creativity, and personalized customer experiences …
Written by:
Chief Executive Officer
Artificial Intelligence (AI) is transforming manufacturing like never before, driving industry efficiency, precision, and innovation.
Written by:
Chief Executive Officer